Data Engineering is the backbone of the data world, where professionals design, build, and maintain the infrastructure that enables data collection, storage, and processing. These experts create pipelines that transform raw data into a structured format, ensuring availability, quality, and accessibility for data scientists and analysts. This blog delves into the critical aspects of Data Engineering, outlining key responsibilities, salary expectations, required qualifications and skills, technical proficiencies, career paths, and future prospects. It highlights Data Engineering’s essential role in enabling organisations to unlock the full potential of their data assets.
Types of Data Engineering Roles:
- Data Engineer – Designs and maintains data pipelines, ETL processes, and cloud-based data storage.
- Data Architect – Oversees the overall data infrastructure and strategy.
- ETL Developer – Specialises in Extract, Transform, Load (ETL) workflows.
- Big Data Engineer – Works with large-scale data processing and distributed systems.
- Data Warehouse Engineer – Manages data storage solutions for structured data.
- Data Platform Engineer – Focuses on scalable data platforms and infrastructure.
Responsibilities:
- Designing and building data pipelines for ingestion, transformation, and storage.
- Developing and managing ETL (Extract, Transform, Load) processes for data integration.
- Working with data lakes, data warehouses, and real-time data processing systems.
- Ensuring data quality, security, and compliance with industry standards.
- Implementing orchestration frameworks like Apache Airflow and AWS Step Functions.
- Optimising data storage and retrieval using SQL, NoSQL, and cloud data solutions.
Salary Expectations:
- Entry-Level: $70,000 – $90,000 per year
- Mid-Level: $110,000 – $140,000 per year
- Senior-Level: $150,000 – $180,000+ per year
What is it about?
Data Engineering focuses on making data accessible and reliable for analysis and decision-making. It involves handling large datasets, ensuring efficient processing, and building scalable infrastructure to support machine learning, analytics, and AI applications.
Qualifications:
- A Bachelor’s or Master’s degree in Computer Science, Data Engineering, or a related field is typically required.
- Industry certifications in AWS, Azure, Google Cloud, or big data technologies are beneficial.
Key Skills:
- Programming Languages: Proficiency in Python, Java, and Scala for data processing.
- Database Management: Experience with SQL (PostgreSQL, MySQL, Redshift, Synapse Analytics) and NoSQL (MongoDB, Cassandra, DynamoDB).
- Data Processing: Hands-on experience with Apache Spark, EMR, Databricks, and Hadoop.
- Data Orchestration: Knowledge of Apache Airflow, Step Functions, or Azure Data Factory.
- Cloud Computing: Proficiency in AWS (S3, Redshift, RDS, Glue, Athena) and Azure (Data Lake, Synapse, IoT Hub, HDInsight).
- Security & Governance: Familiarity with IAM, Key Vault, Macie, and Purview.

Technology Proficiencies and Computing Skills:
- Version Control: Git, GitHub, GitLab
- Infrastructure as Code (IaC): Terraform, CloudFormation, Pulumi
- Streaming & Messaging Systems: Kafka, Kinesis, Event Hubs
- Monitoring & Logging: CloudWatch, ELK Stack, Azure Monitor
A Day in the life of a Data Engineer
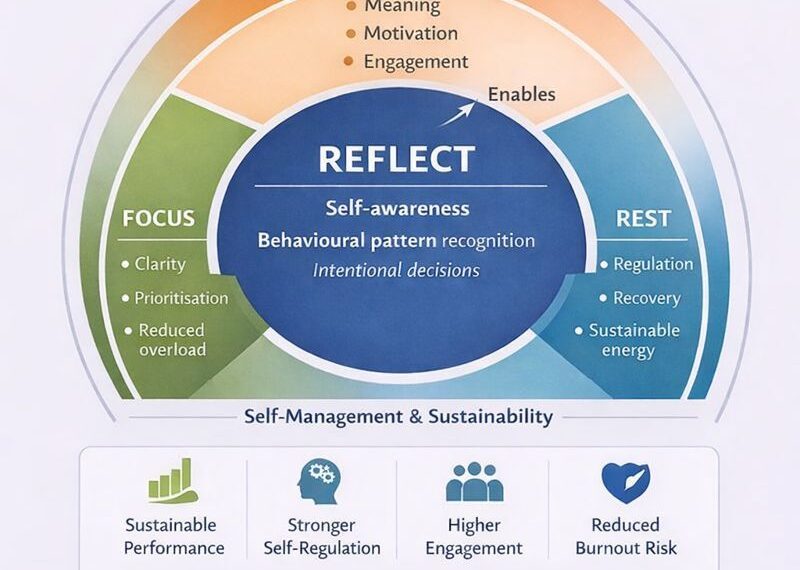
Meta-skills: Self-Management | Universal Skills
They say data is the new oil. If that’s true, then I’m one of the refinery workers—quiet, buried under layers of code, but making sure the whole engine runs. I wake before the world really starts spinning—6:30 AM—and the first thing I check isn’t Instagram or email. It’s the logs from last night’s ETL runs. Not because I have to, but because I want to. That’s what focus feels like—caring deeply about invisible things because they hold everything together.
With a cup of black coffee and some lo-fi beats in the background, I scroll through the logs, watching for anomalies like a hawk. Green lights flash. The data pipelines worked smoothly, with no broken jobs and no failed connections. It’s a small victory—silent but deeply satisfying. That’s what integrity means in this field: knowing your work is invisible unless it fails and still pouring your best into it.
By 8:00 AM, I’m on Zoom with my team. We’re scattered across time zones, but we’ve built a rhythm, a virtual camaraderie. Today, there’s a fire: the Product team is pushing a feature that demands near-real-time data. Our batch pipeline won’t cut it. I suggest migrating parts of it to a streaming architecture using Kafka. Some eyebrows raised. It’s bold but doable. They know I wouldn’t say it if I weren’t ready to take initiative. By 9:00 AM, I’m deep into redesigning a DAG on Apache Airflow, fingers dancing across the keyboard, diagrams forming in my head.
Midway through the day, I take a break and hop on a mentoring call with Aisha, one of our newer engineers. She’s stuck on a data lake partitioning issue, and I guide her through it—not just the technicals but the thinking process. This is where universal skills like digital fluency and coaching come in. Watching her eyes light up when it clicks is more rewarding than any code push.
By late afternoon, I had tested the pipeline again. It worked—clean, fast, and reliable. I sent a quick Slack message to the team: “Real-time feed now live. Data’s flowing.” A chorus of thank-you emojis followed—no spotlight, just silent appreciation.
The sun is setting, and I finally close my laptop. I don’t always get everything right. But every day, I try to show up with adaptability—because the tools keep changing, the data keeps growing, and the future doesn’t wait. I’m not just an engineer. I’m a builder of the unseen, and I wouldn’t trade it for anything.
– By Gabriel Omagwu {Data Engineer @ Data2Bots}
Work Experience:
- Hands-on experience with real-world data engineering projects.
- Internships in data engineering, cloud computing, or big data analytics.
- Contributions to open-source data engineering projects.
Helpful to Have:
- Knowledge of data governance and compliance standards.
- Experience with machine learning pipelines and MLOps.
- Understanding of DevOps practices and CI/CD for data workflows.
Type of Employers:
- Tech companies – Building scalable data infrastructure.
- Financial institutions – Managing massive transaction datasets.
- Healthcare & Biotech – Processing large-scale medical data.
- Retail & E-Commerce – Optimising customer analytics and personalisation.
- Cloud & SaaS Companies – Developing cloud-based data platforms.
Professional Development:
- Keeping up with emerging data technologies through courses and certifications.
- Attending data engineering conferences, workshops, and hackathons.
- Engaging in community-driven open-source projects.
Career Prospects:
Data Engineers have excellent career prospects, with opportunities for advancement into:
- Senior Data Engineer – Lead data teams and strategy.
- Data Architect – Designs enterprise-wide data solutions.
- Big Data Specialist – Managing large-scale distributed data systems.
- Machine Learning Engineer – Developing AI-powered data solutions.
Conclusion
Data Engineering is a critical and rapidly growing field that powers the modern data-driven economy. As businesses continue to harness big data for competitive advantage, skilled Data Engineers will remain in high demand. Professionals can play a pivotal role in building scalable, high-performance data solutions by mastering cloud technologies, big data processing, and data pipeline automation.